-
인덱스 스캔 효율화DataBase/튜닝 2024. 8. 1. 14:14
LOT, 클러스터, 파티션은 랜덤 엑세스 최소화하는 데 매우 효과적인 저장 구조
하지만, 이를 적용하려면, 많은 테스트를 진행해야 한다. (시스템 개발 단계에서 물리 설계가 중요한 이유)
1. 인덱스 탐색
인덱스의 탐색은 수직적 탐색, 수평적 탐색으로 나눌 수 있다.

친절한 SQL 튜닝 화살표로 찾아간 블록에는 자신의 키 값보다 크거나 같은 값을 갖는 레코드가 저장돼 있다.
각 레코드는 하위 노드를 가리키는 블록 주소를 가지고, 하위 노드에는 자신의 키 값보다 크거나 같은 값을 가진 레코드가 저장되어 있다.
LMC는 자식 노드 중 가장 왼쪽 끝에 위치한 값을 가리킴 (부모 노드 A 3보다 작거나 같은 값)
1.1 (=)조건
(1) WHERE C1 = 'B'

친절한 SQL 튜닝 루트 스캔 과정에서 C1='B'로 내려가는게 아니라, 그 왼쪽부터 탐색 시작
WHERE 조건문이 스캔 시작점을 찾는데 유용한 역할 수행
(2) WHERE C1 = 'B' AND C2 = 3

친절한 SQL 튜닝 여기서도 조건절이 스캔 시작점을 찾는데 유용한 역할을 수행하고 있다.
1.2 범위 조건
(1) WHERE C1 = 'B' AND C2 >= 3 (크거나 같음)

친절한 SQL 튜닝 C2 >= 3 조건절이 스캔을 멈추는데 역할은 못했다. 하지만, 시작점을 찾는데 중요한 역할을 했다.
(2) WHERE C1 = 'B' AND C2 <= 3 (작거나 같음)
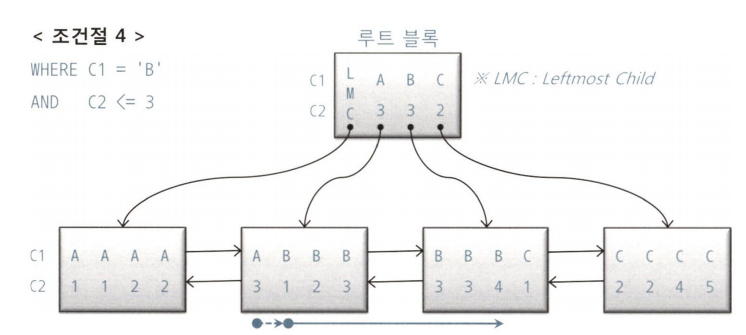
친절한 SQL 튜닝 C2 <= 3 조건절은 수직적 탐색 과정에 전혀 안쓰였지만, 스캔을 멈추는 데는 중요한 역할을 했다.
(3) C1 = 'B' AND C2 BETWEEN 2 AND 3 (선행이 = 이고 후행이 BETWEEN)

친절한 SQL 튜닝 C1과 C2 조건절 모두 스캔 시작과 끝 지점을 결정하는데 역할을 수행
(4) WHERE C1 BETWEEN 'A' AND 'C' AND C2 BETWEEN 2 AND 3

친절한 SQL 튜닝 C1 조건절은 스캔 시작과 끝을 결정하는데 역할을 수행했지만 C2는 스캔량을 줄이는데 거의 역할을 못했다.
결론적으로 SQL에 인덱스 선행 컬럼에 대한 조건이 없거나, = 조건이 아니라면, 인덱스 스캔 과정에서 비효율이 발생한다.
2. 엑세스 조건과 필터 조건

친절한 SQL 튜닝 인덱스 엑세스 조건: 인덱스 스캔 범위를 결정하는 조건 수직적 탐색으로 시작점을 결정하는 데 영향
인덱스 필터 조건: 테이블로 엑세스할지를 결정하는 조건절
인덱스를 이용하던, 테이블을 Full Scan 하든, 테이블 액세스 단계에서 처리되는 조건절은 모두 필터 조건이다.
테이블 필터 조건: 쿼리 수행 다음 단계로 전달하거나 최종 결과집합에 포함할지를 결정
*옵티마이저의 비용 계산 원리
인덱스 수직적 탐색 비용 + 인덱스 수평 탐색 + 테이블 랜덤 엑세스 비용
= 루트와 브랜치 레벨에서 읽은 블록 수 + 리프 블록 스캔 과정에서 읽은 블록 수 + 테이블 엑세스 과정에서 읽은 블록 수
3. 비교 연산자 종류와 컬럼 순서에 따른 군집성
테이블과 달리 인덱스는 같은 값을 갖는 레코드들이 군집해 있다.
= 연산자를 사용해서 앞쪽부터 누락없이 조회하면, 조건절을 만족하는 레코드들이 모두 모여 있다.
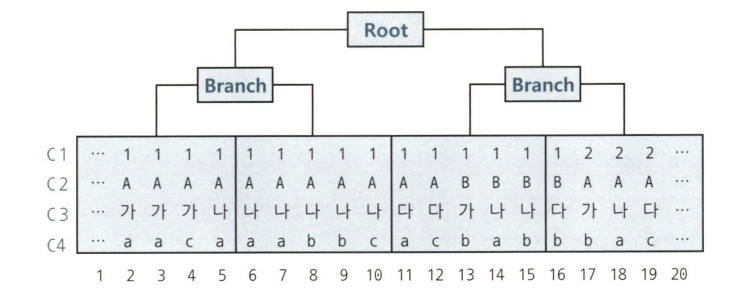
친절한 SQL 튜닝 (1)
WHERE C1 = 1
AND C2 = 'A'
AND C3 ='나'
AND C4 ='a'
> 모두 = 조건이므로, 조건에 만족하는 값들이 모여 있다.
(2)
WHERE C1 = 1
AND C2 = 'A'
AND C3 ='나'
AND C4 >= 'a'
> 선행 조건들이 시작지점, 마지막 조건도 리프의 탐색 시작점을 알려줌
(3)
WHERE C1 = 1
AND C2 = 'A'
AND C3 between '가' and '다'
AND C4 = 'a'
> 선행의 두 조건으로 시작점 (인덱스 엑세스) 3번은 인덱스 필터 조건으로 시작과 끝을 찾을 수 있지만,
마지막 조건에 만족하는 값이 흩어져있다.
(4)
WHERE C1 = 1
AND C2 <= 'B'
AND C3 = '나'
AND C4 between 'a' AND 'b'
> C1과 C2까지 만족하는 테이터는 모여있지만, C3 C4까지 만족하는 레코드는 흩어진다.
위 예를 통해 한가지 규칙을 발견할 수 있다. 인덱스의 순서를 고려했을 때
선행 컬럼이 = 조건인 상태에서 첫 번째 나타나는 범위검색 조건까지만 레코드가 모여있다.
그 이하 조건까지 만족하는 레코드는 비교 연산자 종류에 상관없이 흩어진다.
(5)
WHERE C1 between 1 and 3
AND C2 = 'A'
AND C3 = '나'
AND C4 = 'a'
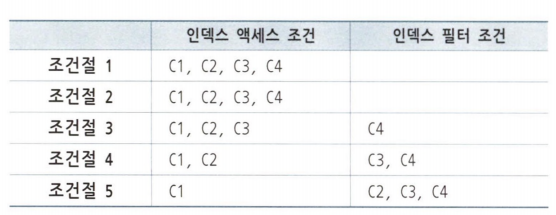
친절한 SQL 튜닝 * 범위검색 조건 맨 처음과 마지막 구간에서 엑세스 조건
조건절 5에서 C2,C3,C4도 C1 = 1인 구간과 C1=3인 구간에서 스캔량을 줄이는데 어느 정도 역할을 수행한다.
where C1 <=3 AND C2 = 'A' and C3 = '나' AND C4 ='a' 조건보다 큰 값을 만나는 순간 멈추기 때문이다.
마찬가지로, 조건절 3과 4의 필터 조건도 범위검색 조건 맨 처음과 마지막 구간에서는 스캔량 줄이는데 역할을 한다.
(다만 무시할만한 수준임)
따라서 몇 가지 케이스를 제외하면 인덱스 컬럼에 대한 조건절은 모두 어느정도 스캔량 줄이는데 영향을 줄 수 있음으로 엑세스 조건에 표시된다.
- 엑세스 조건에 포함 안되는 경우
- 좌변을 가공한 조건
- 왼쪽 % 또는 양쪽 %기호 사용한 like
- 같은 칼럼에 대한 조건절이 두 개 이상일 때, 인덱스 엑세스 조건으로 선택 x 조건절
- OR Expansion 또는 INLIST ITERATOR로 선택되지 못한 OR 또는 IN 조건절
4. 인덱스 선행 컬럼이 동치가 아닐 때 생기는 비효율
인덱스 스캔 효율성은 모두 동치 조건으로 사용할 때 가장 좋다.
인덱스 컬럼 중 일부가 조건절에 없거나 동치 조건이 아니더라도 그것이 뒤쪽 컬럼일 때는 비효율이 없다.
ex)
[아파트시세코드 +평형 + 평형타입 +인터넷매물]
where 아파트시세 =
where 아파트시세 = and 평형 = b
where 아파트시세 = and 평형 b and 평형타입 = c
where 아파트시세 = and 평형 b and 평형타입 between c and b
반면 선행 컬럼이 조건절에 없거나, 부등호, between, like 범위검색 조건이면, 비효율이 발생한다.
이를 항상 기억하자!
5. BETWEEN을 IN-List로 전환
선두컬럼에 범위조건이 걸려있는 경우 이를 IN-List로 바꿔볼 수 있다.
ex)
[인터넷매물 + 아파트시세코드 + 평형 + 평형타입]의 인덱스 순서에서
인터넷 매물에 BETWEEN조건이 걸려있는 경우 이를
WHERE 인터넷매물 in ('1','2','3')
AND 아파트 시세코드 = 'A0101' AND 평형 = '59' AND 평형타입 = 'A' order by 입력일 desc
로 변경해줄 수 있다.
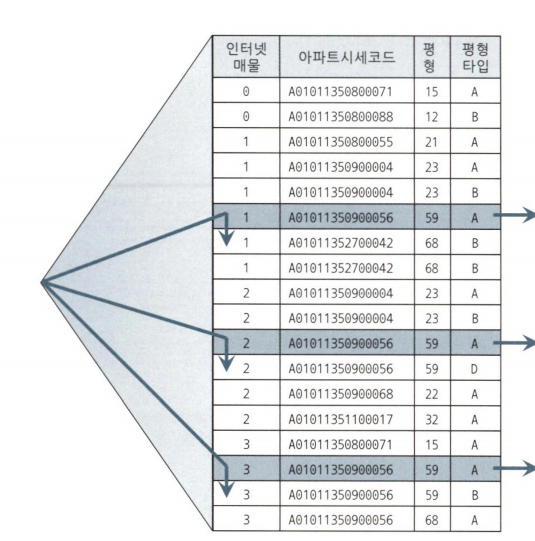
친절한 SQL 튜닝 이와 같이 수직적 탐색이 3번 발생하는 탐색으로 바꿀 수 있다. 이때 실행계획은
INLIST ITERATOR로 발생한다.
수직적 탐색이 3번 발생한다는 말은 UNION ALL로 3번 SELECT하는 것과 같다.
IN-LIST 개수만큼 UNION ALL 브랜치가 생성되고 각 브랜치마다 모든 컬럼을 = 조건으로 검색하므로 선두 컬럼이 BETWEEN일 때 비효율이 사라진다.
(INDEX Sikp Scan을 유도해도 비슷한 효과를 얻을 수 있다.)
IN-List 항목 개수가 늘어날 수 있다면, BETWEEN을 IN-List로 전환하는 방식은 곤란하다.
이럴 때는 NL 방식의 조인문이나 서브쿼리로 구현하자
5.1 BETWENN 조건을 IN-List로 전환할 때 주의사항
1. IN-List의 개수가 많지 않아야 한다. -> 수직적 탐색이 많이 발생해서 비효율적이다.
(특히 리프블록까지의 Depth가 깊다면 더욱 주의해야한다)
2. 탐색해야하는 레코드 수가 적고, 레코드가 밀집해있다면 오히려 비효율적일 수 있다.
(이때도 리프블록까지 찾아가는 비용이 더 들어서 그렇다)
따라서 BETWEEN 조건 때문에 인덱스를 비효율적으로 스캔하더라도, 블록I/O측면에서 더 나은 선택지일 때가 있다.
데이터 분포나 수직적 탐색 비용을 따져보지않고, 무조건 BETWEEN을 IN-List로 변환하지는 말자
6. INDEX Sikp Scan 활용 (BETWEEN 조건 변환)
IN-List 조건으로 변환하면 도움이 되는 상황에서 사용할 수 있는 방법이다.
ex)
create table 월별고객별판매집계 as select rownum 고객번호, '2018' || lpad(rownum/10000),2,'0') 판매월 , decode(mod(rownum,12),1,'A','B') 판매구분 , round(dbms_random.value(1000,100000),-2)판매금액 from dual connect by level <= 1200000;2018년 1월부터 12월까지 월별로 10만개 판매 데이터 입력
판매구분값별로 'A'가 10만개 'B'가 110만개이다. 이 테이블을 이용해 아래와 같은 COUNT 쿼리를 수행하려고 한다.
select count(*) from 월별고객판매집계 t where 판매구분 = 'A' and 판매월 between '201801' and '201812'해당 쿼리를 최적화하기 위해서는 판매구분이 선두에 위치하도록 인덱스를 구성해야한다.
인덱스를 이와 같이 구헝하면 실행계획은 다음과 같다.

친절한 SQL 튜닝 테이블 엑세스는 발생하지 않지만, 281개의 블록 I/O가 발생한 것을 확인할 수 있다.
이번엔 BETWEEN 조건을 선두로 인덱스를 변경하면 다음과 같다.

친절한 SQL 튜닝 블록 IO가 3090개 발생했다. 이는 판매구분 A 레코드가 각 판매월 앞에 위치하며, 전체 120만개의 8.3%만 차지하기 때문이다. (서로 너무 멀리 떨어져있다)
이제 이를 IN-LIST로 변경해서 쿼리를 날려보자

친절한 SQL 튜닝 기존 BETWEEN보다 10배정도 성능이 좋아졌다. 비록 브랜치 블록을 열두번이나 탐색했지만, 리프블록 스캔의 비효율을 제거했기 때문이다.
마지막으로 INDEX Skip Scan을 유도해보자

친절한 SQL 튜닝 IN-LIST와 유사한 혹은 좀 더 좋은 성능을 내는 것을 볼 수 있다.
선두 컬럼이 BETWEEN 조건이 걸려서 데이터들이 멀리 떨어져 있을 때, INDEX Skip Scan은 좋은 성능을 낸다.
7. IN 조건은 = 인가?
IN조건은 = 이 아니다, 인덱스를 어떻게 구성하느냐에 따라 성능이 달라질 수 있다.
select * from 고객별가입상품 where 고객번호 = cust_no and 상품ID in ('NH00037','NH00041','NH00050')7.1 인덱스 [상품 ID+ 고객번호]
고객별로 평균 세 건의 상품을 가입한다고 가정하자, 인덱스를 [상품 ID+ 고객번호] 순으로 생성하면, 같은 상품은 고객번호 순으로 정렬된 상태로 리프 블록에 저장된다.
반면, 같은 고객번호는 상품ID를 기준으로 흩어진 상태가 된다.
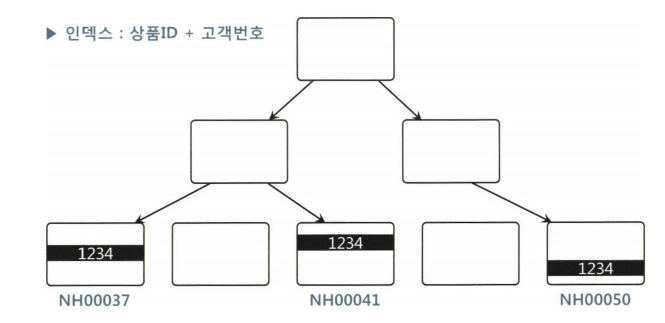
친절한 SQL 튜닝 인덱스가 위와 같다면, IN-List 방식으로 푸는 것이 효과적이다. (이와 같은 경우는 반드시 이렇게 푸는 것이 효과적이다)
7.2. 인덱스 [고객번호+ 상품ID]
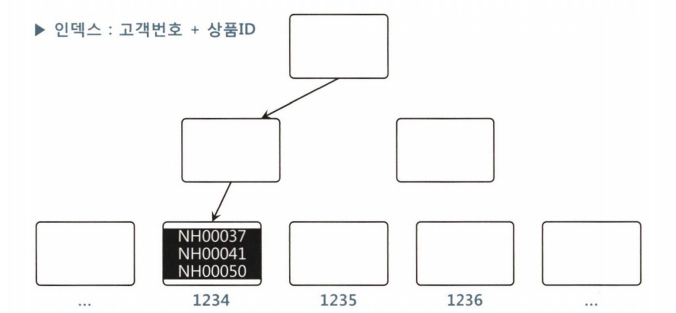
친절한 SQL 튜닝 여기서도 상품ID를 IN-List 방식으로 풀면 수직적으로 세 번 탐색하는 과정을 거친다
그렇지 않으면, 조건절 상품 ID를 인덱스 필터조건으로 처리한다. 이때 고객ID에 상품이 근접해있기 때문에 블록 IO가 4번만 발생한다. (혹은 세 개)
정리하자면, IN조건과 =은 다르다, IN 조건이 = 이되려면, IN-List 방식으로 풀려야한다.
그렇지 않으면, IN은 필터 조건으로 분류된다.
따라서 IN 조건이 항상 =은 아니며, 위와 같은 상황에선 IN-List보다 필터 조건으로 사용되는 편이 낫다.
7.3 NUM_INDEX_KEYS 힌트 활용
IN-LIST를 엑세스 조건 또는 필터 조건으로 유도하는 방법
(1) 필터 조건 유도
- num_index_keys 활용
select /*+ num_index_kyes(a 고객별가입상품_x1 1) */ * from ...3번째인자의 1은 첫 번째 컬럼까지만 엑세스 조건으로 사용하라는 의미다.
- 인덱스 컬럼 가공
select * from 고객별가입상품 where 고객번호 = :cust_no and 상품ID||'' in ('NH00037','NH00041','NH00050')(2) 엑세스 조건 유도
select /*+ num_index_kyes(a 고객별가입상품_x1 2) */ * from ...
8. BETWEEN과 LIKE 스캔 범위 비교
날짜 데이터 조건에서 LIKE 연산자를 많이 사용한다. (BETWEEN을 사용할 수도 있지만, LIKE가 더 편하다!)
select * from 월별고객별판매집계 where 판매월 like '2019%';LIKE와 BETWEEN은 둘 다 범위검색 조건으로, 앞서 말한 비효율이 발생한다.
하지만, 데이터의 분포와 조건절 값에 따라 인덱스 스캔량이 서로 다를 수 있고, 이때 LIKE보다 BETWEEN이 더 나은 성능을 내는 경우가 많다!
ex) [판매월 + 판매구분] 인덱스 판매는 'A'와 'B'로 구분하고 각각 90% 10% 비중으로 차지하는 상황에서 스캔량 비교
--조건절 1 WHERE 판매월 BETWEEN '201901' and '201912' and 판매구분 = 'B' --조건절 2 WHERE 판매월 LIKE '2019%' and 판매구분 ='B'조건절 1은 판매월이 '201901'이고 판매구분이 'B'인 첫 레코드를 스캔 시작점으로 삼는다.
반면 조건절2는 판매월이 201901인 첫 번째 레코드를 스캔 시작점으로 삼는다.
만약, 판매월이 201900으로 저장돼 있다면 그 값도 읽어야 하므로 판매구분이 B인 지점으로 바로 내려갈 수 없다.

친절한 SQL 튜닝 이와 같이 같은 범위 조건이더라도, 데이터의 비중에 따라, BETWEEN이 조금 더 나은 탐색 성능을 보일 수 있음으로, 둘 중 선택해야하는 상황에선 BETWEEN을 사용하자
9. 범위검색 조건을 남용할 때 생기는 비효율
사용자 입력과 선택에 따라 조건절을 다양하게 구성해야하는 경우 SQL을 간편하게 작성하기 위해 조건절을 LIKE로 구사하는 경우가 종종 있다.
이때 해당 컬럼이 인덱스 구성 컬럼일 때는 주의가 필요하다.
ex) 회사코드, 지역코드, 상품명을 입력하여 가입상품 테이블에서 데이터를 조회하는 프로그램
- 조회 화면에서 회사코드는 반드시 입력하지만, 지역코드는 입력하지 않을 수도 있다.
- 상품명은 단어 중 일부만 입력 할 수 있다.
- 이때 인덱스는 회사코드 + 지역코드 + 상품명 순으로 구성되어 있다.
해당 조건을 만족하기 위한 쿼리는 다음과 같이 작성할 수 있다.
-- 회사코드, 지역코드, 상품명을 모두 입력 SELECT 고객ID, 상품명, 지역코드 FROM 가입상품 WHERE 회사코드 = :com AND 지역코드 :reg AND 상품명 LIKE :prod || '%' -- 회사코드, 상품명만 입력할 때 SELECT 고객ID, 상품명, 지역코드 FROM 가입상품 WHERE 회사코드 = :com AND 상품명 LIKE :prod || '%'쿼리에 대한 인덱스 탐색 결과는 각각 다음과 같다.
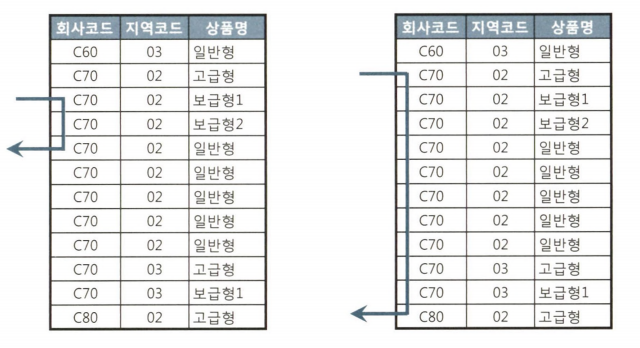
친절한 SQL 튜닝 인덱스의 중간 컬럼에 대한 조건이 없을 때는 어쩔 수 없이 넓은 범위를 스캔해야한다.
인덱스 조건이 모두 있다면, 필요한 만큼만 스캔할 수 있다.
이때 프로그램 담당 개발자가 두 가지 상황을 SQL 하나로 처리하려고 아래와 같이 조건절에 LIKE 연산자를 사용할 수도 있다.
SELECT 고객ID, 상품명, 지역코드 FROM 가입상품 WHERE 회사코드 =: com AND 지역코드 LIKE :reg || '%' AND 상품명 LIKE :prod || '%'이때 인덱스 탐색은 각각 다음과 같다.
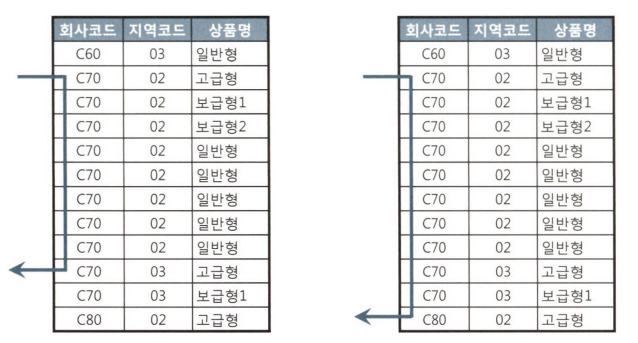
친절한 SQL 튜닝 모든 컬럼을 입력했음에도, 인덱스 탐색이 길어지는데, 이는 지역코드가 범위조건으로 바뀌면서, 상품명이 인덱스 필터조건으로 바뀌었기 때문이다.
또한 BETWEEN 조건을 사용할 수도 있다.
SELECT 거래일자, 종목코드, 투자자유형코드, 주문매체코드, 체결건수, 체결수량, 거래대금 FROM 일별종목거래 WHERE 거래일자 BETWEEN 시작일자 AND 종료일자 AND 종목코드 BETWEEN 종목1 AND 종목2 AND 투자자유형코드 BETWEEN 투자자유형1 AND 투자자유형2 AND 주문매체구분코드 BETWEEN 주문매체구분1 AND 주문매체구분2개발 생산성만 놓고 보면 좋은 아이디어일 수 있지만, 스캔 효율을 고려한다면 사용을 자제해야할 패턴이다.
인덱스 칼럼에 범위검색 조건을 남용하면 인덱스 스캔 비효율이 생긴다.
따라서 인덱스 칼럼에 대한 비교 연산자는 신중하게 선택해야 한다.
10. 다양한 옵션 조건 처리 방식의 장단점 비교
(10.1) OR 조건 활용
select * from 거래 where (:cust_id is null or 고객ID = :cust_id) and 거래일자 between :dt1 and dt2흔히 실수하는 이 방식은 옵션 조건 컬럼을 선두에 두고 인덱스를 구성하여, 인덱스를 사용할 수 없다는 데 있다.
따라서 인덱스 선두 컬럼에 대한 옵션 조건에 OR 조건을 사용하지 말자
[거래일자 + 고객ID] 순으로 인덱스를 구성한다고해도, 고객 ID는 필터 조건으로 사용된다.
따라서 스캔 단계에서 효율성을 찾기가 힘들기 때문에 고객ID는 인덱스에 포함할 필요조차 없다.
인덱스에 포함되지 않는 컬럼에 대한 옵션 조건은 테이블에서 필터링할 수 밖에 없으므로 OR조건을 사용해도 무방하다.
* OR조건
- 인덱스 엑세스 조건으로 사용 불가
- 인덱스 필터 조건으로 사용 불가
- 테이블 필터 조건으로만 사용 가능
- 단 인덱스 구성 컬럼 중 하나 이상이 Not Null 컬럼이면, 18c부터 인덱스 필터 조건으로 사용 가능
(10.2) LIKE/BETWEEN 조건 활용
변별력이 좋은 필수 조건이 있는 상황에서 사용하는 것은 나쁘지 않다. 필수 조건 컬럼을 인덱스 선두에 두고 엑세스 조건으로 사용하면, LIKE/BETWEEN이 인덱스 필터 조건이어도 충분히 좋은 성능을 낼 수 있기 때문이다.
문제는 필수 조건의 변별력이 좋지 않을 때다. 아래 SQL에서 상품대분류코드만으로 조회할 때는 Table Full Scan이 유리하다.
하지만, 옵티마이저는 상품코드까지 입력할 때를 기준으로 Index Range Scan을 선택한다.
select * from 상품 where 상품대분류코드 = "prd_lcls_cd" and 상품코드 like :prd_cd || '%'이때 사용자가 상품코드까지 입력하면 최적의 성능을 내겠지만 그렇지 않으면 문제 발생함
- LIKE/BETWEEN 패턴을 사용할 때 주의사항
- 인덱스 선두 컬럼
인덱스 선두 컬럼에 대한 옵션 조건을 LIKE/BETWEEN 연산자 처리하는 것은 금물
select * from 거래 where 고객ID like :cust_id || '%' and 거래일자 between :dt1 and :dt2고객 ID가 변별력이 좋아서 상관없을 수 있지만, 고객ID를 입력하지 않으면, 모든 데이터 스캔함
선두컬럼이 들어올 수도 있고, 아닐 수도 있는 경우에 LIKE 패턴을 사용해야하면, 반드시 입력해야하는 거래일자를 선두로 바꾸자
2. NULL 허용 컬럼에 대한 옵션 조건을 LIKE/BETWEEN 연산자로 처리하는 것도 금물
성능을 떠나 결과 집합에 오류가 발생할 수 있다. :cust_id변수에 NULL을 입력하면 null like '%'가 된다 이런 경우 아예 sql을 뽑아낼 수 없다 주의하자
3. 숫자형에 LIKE는 금물
자동형변환이 일어난다.
4. LIKE 옵션 조건에 사용할 때는 컬럼 값 길이가 고정적이어야 한다.
컬럼이 김훈, 김훈남 등 다른 값이 입력될 수 있을 때 김훈만 입력해도 김훈으로 시작하는 모든 데이터를 찾기 때문에 효율이 떨어질 수 있다.
11. 범위조건 비효율을 피하는 방법
11.1 UNION ALL 활용
아래와 같이 UNION ALL을 사용하는 방법도 있다. 변수 값을 입력했는지에 따라 SQL을 하나만 실행하게 하는 것이다.
select * from 거래 where :cust_id is null and 거래일자 between :dt1 and :dt2 union all select * from 거래 where :cust_id is not null and 고개ID = :cust_id and 거래일자 between :dt1 and dt2이와 같이 SQL을 작성하면 비효율이 없다 유일한 단점은 SQL양이 길어진다는 것 뿐이다.
11.2 NVL/DECODE 활용
NVL과 DECODE를 활용한 패턴을 사용할 수도 있다.
select * from 거래 where 고객ID = nvl(:cust_id, 고객ID) and 거래일자 between :dt1 and :dt2 select * from 거래 where 고객ID = decode(:cust_id,null, 고객ID, :cust_id) and 거래일자 between :dt1 and :dt2cust_id 변수에 값을 입력하지 않으면, 거래일자가 선두인 인덱스를 사용, 변수를 입력하면 고객id가 선두인 인덱스를 사용한다.
고객ID 컬럼에 함수를 사용했는데 인덱스를 사용할 수 있는 것은 OR-Expansion 쿼리변환이 일어났기 때문이다.
UNION ALL 방식으로 쿼리를 변환해준다.
이 방식의 장점은 옵션 조건 컬럼을 인덱스 엑세스 조건으로 사용할 수 있다는 점이다.
단점은 NULL 허용 컬럼에 사용할 수 없다는 점이 있다.
*옵션 처리용 NVL/DECODE 함수를 여러 개 사용하면 그중 변별력이 가장 좋은 컬럼 기준으로 한 번만 OR Expansion이 일어난다는 사실도 기억하자
* 변별력이 좋다는 말은 그 값이 고유하다는 뜻이다
'DataBase > 튜닝' 카테고리의 다른 글
조인 튜닝 - NL 조인 (0) 2024.08.07 인덱스 설계 (0) 2024.08.06 인덱스 튜닝(2) - 부분범위 처리 활용 (0) 2024.07.19 인덱스 튜닝 (1) - 기본 이론 (0) 2024.07.18 여러가지 인덱스 스캔 방식 (0) 2024.07.18 - 엑세스 조건에 포함 안되는 경우